DeZeroの使い方
関数の最小値(勾配降下法)
次の式で,$z$の最小値となる$x$と$y$を求める($x,y$は実数). $$ z = (x-2)^2 + (y-3)^2 $$ $z=x^2+y^2$のグラフの形がこちらであるため, これを$x$軸正の方向に$2$,$y$軸正の方向に$3$だけ平行移動させたものがこのグラフの形である.
次のコードで,$x$と$y$の初期値を$0$として,z.backward()をしたあとに,x.gradとy.gradを表示する.これは何を表しているのか.
| |
| |
backwardメソッドでは,$z$の各変数についての偏微分を計算している.この場合は,次のようになる.
$$
\frac{\partial z}{\partial x} = 2(x-2) = 2x-4
$$
$$
\frac{\partial z}{\partial y} = 2(y-3) = 2y-6
$$
そして,gradは,変数がその値であるときの偏微分を表している.
$$
\frac{\partial z}{\partial x} (0,0) = -4
$$
$$
\frac{\partial z}{\partial y} (0,0) = -6
$$
偏微分の図形的な意味は勾配(gradient)である.点$(0,0)$から,これらの偏微分をベクトルとして表した$(-4,-6)$の方向に移動すると,$z$の値が最も大きくなる.これを勾配ベクトルと呼び,次のように記号$\nabla$で表す. $$ \nabla z = \left( \frac{\partial z}{\partial x}, \frac{\partial z}{\partial y} \right) = \left( -4, -6 \right) $$ まとめると,勾配ベクトル$\nabla z(x,y)$は,次の意味を持つ(証明1).
- $(x,y)$からちょっと動いたときに,$z$の値が最も大きくなる方向を示す.
- その方向に,$C$だけ動くと,$z$の値が$C||\nabla z||$くらい増える.
- $||\nabla z||$は勾配ベクトルの大きさである.
この性質を利用すると,できるだけ小さい値$z$を求めるためには,$z$の勾配ベクトルの逆の方向に少し動くことを繰り返せば良いと考えられる.この手法を勾配降下法と呼ぶ.
これをDeZeroで実装すると,次のようになる.
| |
| |
注意するべきは,
x.cleargrad()とy.cleargrad()で,x.gradとy.gradを初期化している.x.gradではなくx.grad.dataを使っている.x.gradが整数型ではなく,Variableという型であるため.
線形回帰
問題設定
$y=ax+b$のような線形関数で,与えられた点$(x_i,y_i)$の集合を「最もよく近似する」$a$と$b$を求める問題を線形回帰と呼ぶ.まず,次のようなデータセットで試す.
| |
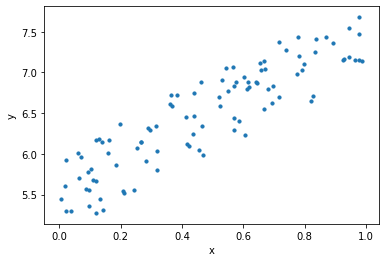
人間の感覚により,なんとなく真ん中に直線が引けそうなことはわかる.
問題となるのが,何をもって「最もよく近似している」直線であると判断するかである.これは,いくつかの指標が考えられる.今回は,次の式で表される「平均二乗誤差」(mean squared error)を用いる. $$ L = \frac{1}{N} \sum_{i=1}^N (y_i - (ax_i + b))^2 $$ この値が小さいほど,直線がデータに近似しているということにする.このような予測したパラメータの悪さを表す指標を損失関数(loss function)と呼ぶ.
実装
複数の点$(x_i,y_i)$があるが,これをまとめて一つの変数として扱うために,行列を用いる.
$y=ax+b$の式を行列で表すと,次のようになる.行列を扱うことのできるライブラリを使うと,簡単に計算ができる.
$$
\begin{pmatrix}
y_1 \\
y_2 \\
\vdots \\
y_N
\end{pmatrix}
=
a
\begin{pmatrix}
x_1 \\
x_2 \\
\vdots \\
x_N
\end{pmatrix}
+
\begin{pmatrix}
b \\
b \\
\vdots \\
b
\end{pmatrix}
$$
一次関数の計算をpredict関数で行うとすれば,次のようになる.ここでは,$a$の代わりにWで実装している.
| |
また,numpyの機能を使うと損失関数は次のように実装できる.
| |
あとは,損失関数上での勾配ベクトルを求め,パラメータを更新するだけである.
勘違いをしがちなのが,次の点だ.
- $x_1,x_2,\dots,x_N,y_1,y_2,\dots,y_N$は,変数ではなく定数である.
- 変数であるのは,$y=ax+b$における$a$と$b$のみである.
- つまり,損失関数は,$a$と$b$の関数である.その損失関数は,係数や定数項に$x_i,y_i$がたくさん入っている複雑な関数である.
非線形なデータ
この世の全てのデータが線形の関係にあるわけではない.$y=\sin x$のような非線形なデータに対して,線形な関数を使って予測すると,次のような結果になる.
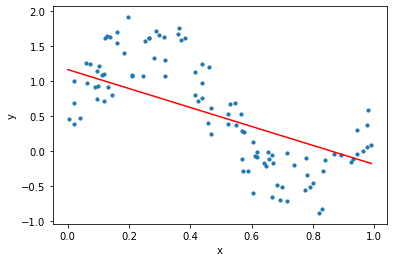
三角関数に準じたデータであるが,線形の形で近似するとなんともアバウトな結果になる.
ここでニューラルネットワークの概念が登場する.ニューラルネットワークは,線形な関数(線形変換,あるいはアフィン変換)と非線形な関数(活性化関数と呼ばれる)を組み合わせることで,非線形な関数を表現することができる.
活性化関数の例としては,シグモイド関数やReLU関数などがある.
$$
\begin{align*}
\text{シグモイド関数} \quad &\sigma(x) = \frac{1}{1 + \exp(-x)} \\
\text{ReLU関数} \quad &\text{ReLU}(x) = \max(0, x)
\end{align*}
$$
DeZeroでは,これらの関数はdezero.functionsに実装されている.線形関数もF.linearで実装されている.さっきのコードF.matmul(x, W) + bは,F.linear(x, W, b)と書き換えられる.今回は,線形関数,シグモイド関数,線形関数の3つの層を組み合わせる.
| |
各層で起こっていることを順に説明をする.入力と出力の次元はそれぞれ1と1である.中間層(隠れ層)の次元は10とする.
- 第$1$層.入力は$1$次元で,$10$次元の$W$と$b$を用いて線形変換され,$y_1,y_2,y_3,\cdots,y_{10}$が得られる.
$$ \begin{pmatrix} y_1 & y_2 & \cdots & y_{10} \end{pmatrix} = \begin{pmatrix} x \end{pmatrix} \begin{pmatrix} w_{1} & w_{2} & \cdots & w_{10} \end{pmatrix} + \begin{pmatrix} b_{1} & b_{2} & \cdots & b_{10} \end{pmatrix} $$
- 次に,第$2$層目で,$y_1,y_2,y_3,\cdots,y_{10}$をそれぞれシグモイド関数に入力する. $$ y_1 \leftarrow \sigma(y_1) \\ y_2 \leftarrow \sigma(y_2) \\ \vdots \\ y_{10} \leftarrow \sigma(y_{10}) $$
- 最後に,第$3$層目で,$y_1,y_2,y_3,\cdots,y_{10}$をそれぞれ線形変換する.
$$ \begin{pmatrix} y \end{pmatrix} = \begin{pmatrix} y_1 & y_2 & \cdots & y_{10} \end{pmatrix} \begin{pmatrix} w_1 \\ w_2 \\ \vdots \\ w_{10} \end{pmatrix} + \begin{pmatrix} b \end{pmatrix} $$
注意するべきは,数式で$x$はスカラー量のように見えているが,実際は,x = np.random.rand(100, 1)のような行列であることである(この場合$100$行$1$列の行列).
最終的には次のようなコードになる.
| |